简介
Jaeger是 Uber 推出的一款开源分布式追踪系统(已从CNCF毕业),兼容 OpenTracing API。 它用于监视和诊断基于微服务的分布式系统,功能包括:
- 分布式上下文传播
- 分布式链路跟踪
- 服务依赖分析
示例
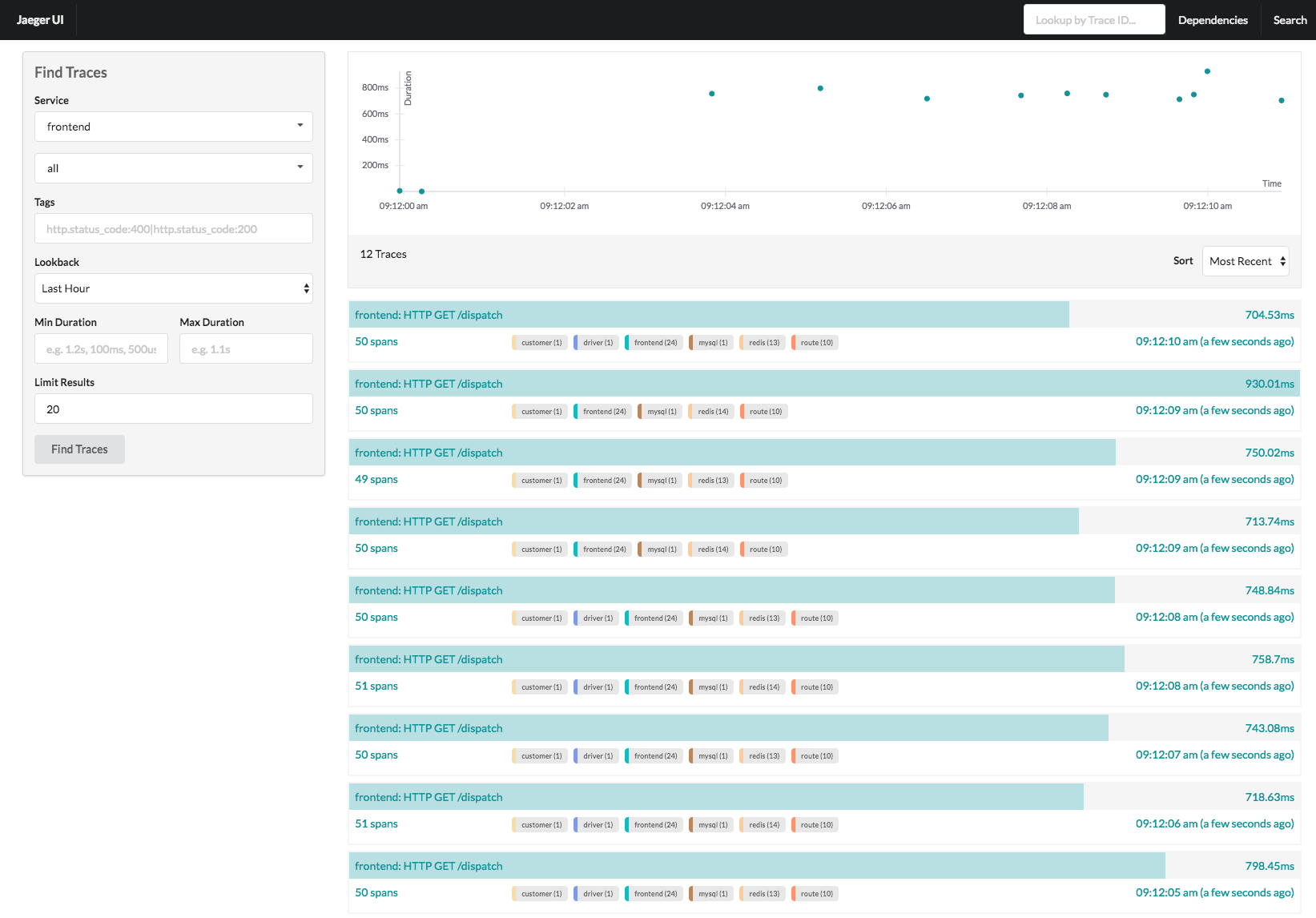
Trace列表视图
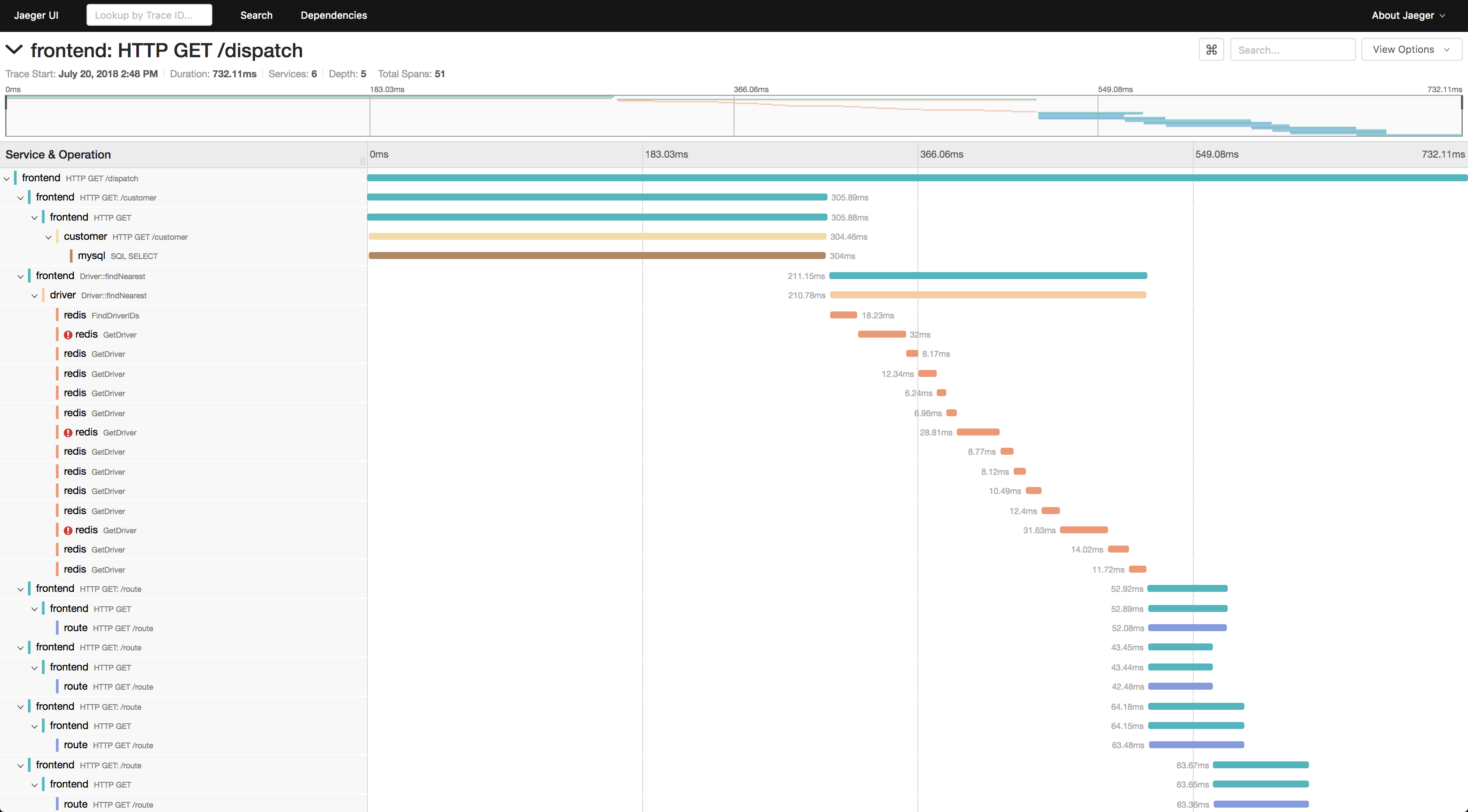
Trace明细视图
技术栈
- 基于Go实现
- 数据支持多种类型的后端存储
- Cassandra 3.4+
- Elasticsearch 5.x, 6.x, 7.x
- Kafka
- memory storage
架构
Jaeger可以作为单个进程进行部署,也可以作为可扩展的分布式系统进行部署。
Jaeger 主要由以下几部分组成,架构非常清晰:
- Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent.
- Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节.
- Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。 当前,我们的管道会分析数据并为其建立索引,执行任何转换并最终存储它们。 Jaeger的存储设备是一个可插拔组件,目前支持 Cassandra, Elasticsearch and Kafka 存储.
- Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示.
- Ingester - 后端存储被设计成一个可插拔的组件,支持将数据写入 Cassandra, Elasticsearch.
Jaeger包含两种架构方案:
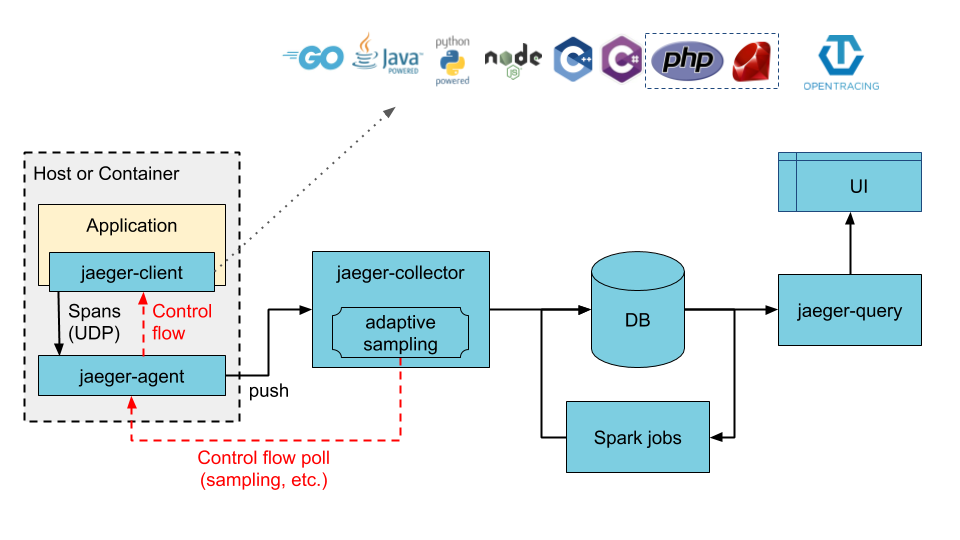
一、收集器数据直接写入存储架构(tracing数据直接写入存储)
二、收集器数据缓冲后异步写入存储架构(tracing数据通过kafka缓冲后再异步消费写入存储)
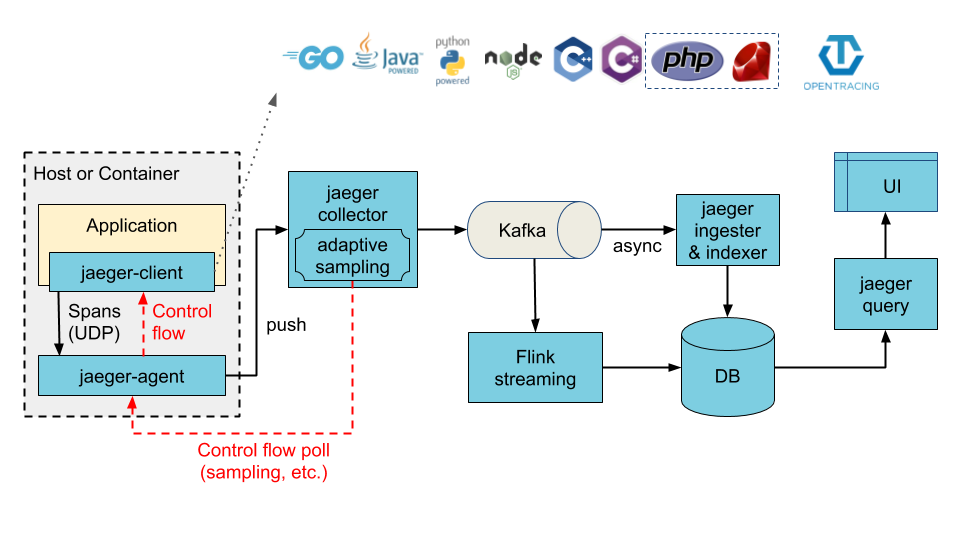
个人推荐采用第二种架构方式部署
部署
为了快速搭建Jaeger环境,这里安装基于Helm部署(需要先搭建 Kubernetes 集群),可以参考前面写的文章来搭建。从 https://github.com/jaegertracing/helm-charts/tree/master/charts/jaeger 这里可以找到详细的部署流程,可以一步一步跟着执行部署。这里采用 收集器数据直接写入存储架构 部署
1 | helm install jaeger jaegertracing/jaeger |
官方推荐使用jaeger-operator来部署,可参考: https://www.jaegertracing.io/docs/1.17/operator/
安装完成后查看服务状态
1 | kubectl get svc |
要访问jaeger ui 需要查看jaeger-query项目对外暴露的端口,我们看到通过helm安装,我们采用的默认配置,这里的网络类型是ClusterIP,如果想外网访问可以先临时改成NodePort的方式,执行如下命令编辑对应配置:
1 | kubectl edit service jaeger-query |
找到最下面的ClusterIP改成NodePort保存即可,保存后会自动生效
1 | kubectl get svc |
可以发现现在jaeger-query的网络类型已经变成了NodePort,现在可以通过流量访问Jaeger Ui了
这里的地址是 http://47.57.100.110:31067/search (注意,IP地址及端口根据自己控制台的实际输出填入就行)
进入页面后可以到刚才部署的UI界面,并查询jaeger-query项目本身的tracing信息。
我在列表页面找到一个trace_id: 73c00aa573bf1ed0 临时保存下它,后面分析会用到,打开后界面如下。
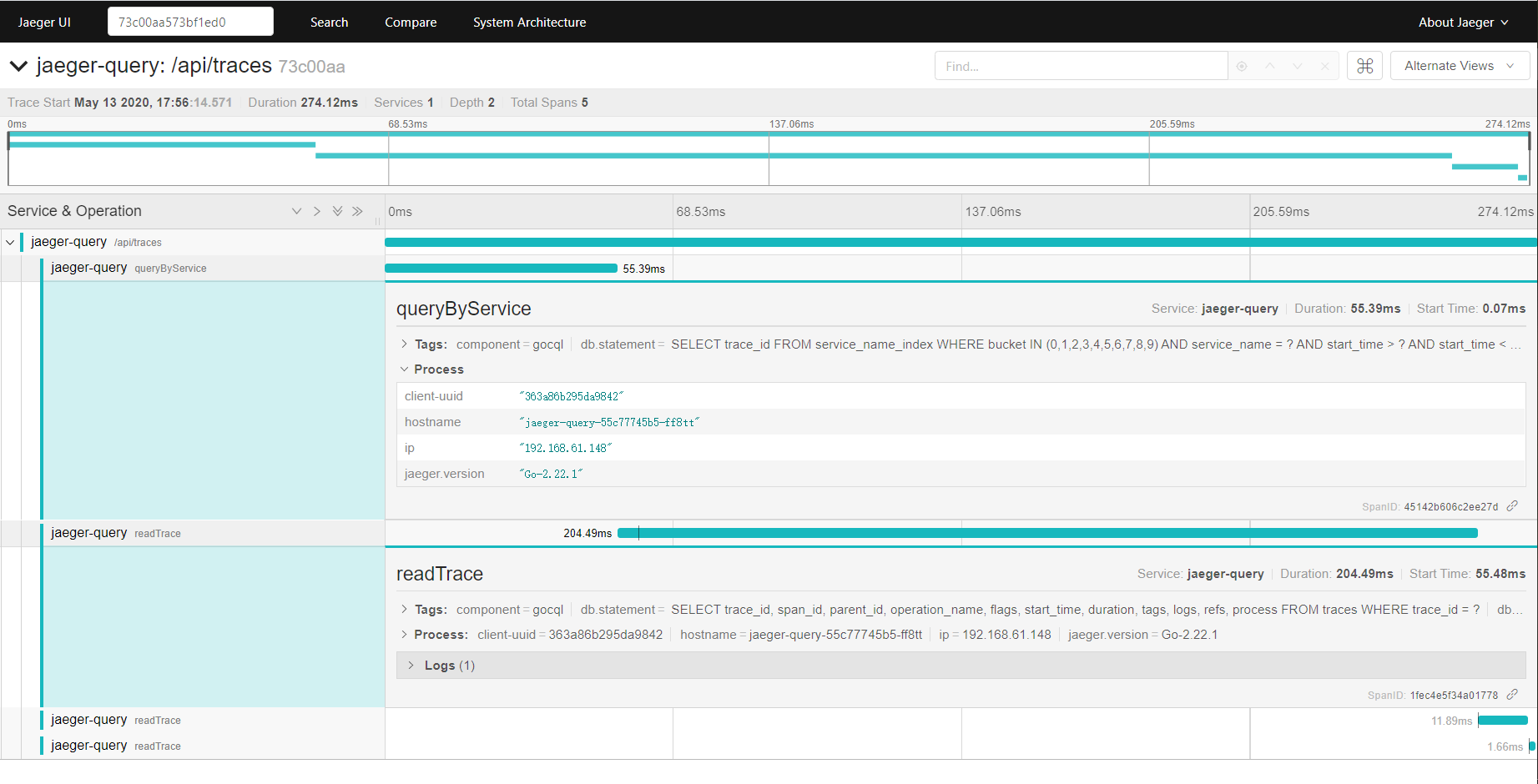
traces存储结构
我们可以在jaeger源代码中找到后端cassandra的存储结构,具体信息可以看这里,位置比较隐蔽:
https://github.com/jaegertracing/jaeger/blob/master/plugin/storage/cassandra/schema/v001.cql.tmpl
不过我们可以登录Pod查看创建后的数据结构信息(cassandra)。让我们一探究竟,首先登入cassandra对应的docker镜像,然后通过cql 连接cassandra集群。
如果对cql不了解的可以查看对应文档: https://cassandra.apache.org/doc/latest/cql/
1 | kubectl exec -it jaeger-cassandra-0 --container jaeger-cassandra -- /bin/bash |
进入对应的space,查看里面对应的表信息
1 | cqlsh> desc keyspaces; #查看有哪些keyspaces |
我们可以一个一个的表信息查看。这里我们主要看下保存我们trace信息的表 service_name_index
1 | cqlsh:jaeger_v1_test> desc traces; |
还记得我们开始保存的那个trace_id: 73c00aa573bf1ed0 么,现在我们可以在这个表中查看它是如何保存的,我们可以使用下面的cql进行查询,查询前需要对界面上的trace_id进行补位填充0x0000000000000000 ,这里一定要注意,最终在cql里面查询的trace_id为:0x000000000000000073c00aa573bf1ed0。
1 | cqlsh:jaeger_v1_test> expand on; |
因为找到这个trace_id包含了5个span,所以这里查询出来了5条记录,可以通过这段文本及上面的图片进行一一观察,可以发现存储结构还是非常清晰的,UI界面需要展示的信息基本都可以很容易从里面取到。
我们再回过头来看看jaeger client 库thrift的结构(源码见:jaeger.thrift)
1 | # 标签 |
基本上可以跟存储的数据结构一一对应上。
采样策略
Jaeger客户端支持4种采样策略,分别是:
- Constant (
sampler.type=const) 采样率的可设置的值为 0 和 1,分别表示关闭采样和全部采样 - Probabilistic (
sampler.type=probabilistic) 按照概率采样,取值可在 0 至 1 之间,例如设置为 0.5 的话意为只对 50% 的请求采样 - Rate Limiting (
sampler.type=ratelimiting) 设置每秒的采样次数上限 。 例如,当sampler.param = 2.0时,它将以每秒2条迹线的速率对请求进行采样。 - Remote (
sampler.type=remote) 此为默认策略。 采样遵循远程设置,取值的含义和probabilistic相同,都意为采样的概率,只不过设置为remote后,Client 会从 Jaeger Agent 中动态获取采样率设置。
为了最大程度地减少开销,Jaeger默认采用 0.1% 的采样策略采集数据 (1000次里面采集1次)。
客户端
所有Jaeger客户端库都支持OpenTracing API ,下面这些都是官方支持的客户端库
| 语言 | GitHub Repo |
|---|---|
| Go | jaegertracing/jaeger-client-go |
| Java | jaegertracing/jaeger-client-java |
| Node.js | jaegertracing/jaeger-client-node |
| Python | jaegertracing/jaeger-client-python |
| C++ | jaegertracing/jaeger-client-cpp |
| C# | jaegertracing/jaeger-client-csharp |
其他语言的客户端库还在开发中,具体进展可以来这里查看 issue #366